SQL调优的流程
SQL调优无论在实际工作中还是在面试过程中都是考查的重点,在文章中我将从慢查询分析和索引两个角度来介绍SQL调优的一点思路。
慢查询分析
SQL优化并不是漫无目的一条条去 explain SQL语句,需要具备针对性,所以我们只需要对执行时间超出我们预期的SQL进行针对的调整,那么慢查询分析日志就是帮我们快速定位超预期执行时间的SQL的一个有力工具。
打开慢查询分析日志开关
打开慢查询分析日志的开关的两种方式:1.修改配置文件,2.设置参数。我们下面使用设置参数的方式来演示:
登入MySQL(略)
查看慢查询日志分析文件的配置信息:
show variables like 'slow_query%'; |
- 得到如下的配置信息:
+---------------------+-------------------------------------------------+ |
把slow_query_log 的值 OFF 设置为 ON,即打开慢查询分析日志记录。记录的日志文件会保存在slow_query_log_file 的 Value 所指向的路径文件中,如果需要也可以对其进行修改。
set global slow_query_log = 'ON'; |
更改慢查询分析的默认时间
MySQL默认是的时间是 10 sec,显然时间太长了,我们可以修改这个参数为自己的心里预期时间:
查看默认时间配置:
show variables like 'long_query%'; |
得到如下的配置信息:
+-----------------+-----------+ |
修改默认的时间(单位:秒),一般在项目中可以设置为0.1秒,即100毫秒。为了演示方便下面将其设置为1秒:
set global long_query_time = 1; |
修改完所有参数之后要quit;重新登入数据库才能保证已设置的参数生效。
构造一个慢的SQL测试语句
select sleep(3); |
查看慢查询分析的日志文件
温馨提示:在查看慢查询分析文件之前要quit; MySQL。
通过查看慢查询分析的日志文件,我们可以了解项目中哪些SQL超出了我们设置的预期执行时间,然后针对其进行优化:
tail /var/lib/mysql/TechBird-Macbook-slow.log |
日志如下:
Time: 2021-04-01T06:59:15.149853Z |
通过查看日志,可以准确的定位出是这条select sleep(3);执行超出了预期时间,从而利用下文所介绍的方法针对其进行优化。
索引
我们已经定位出了执行超出预期时间的SQL语句,一般来说可以使用explain工具对其进行分析定位问题,总结起来就是如下几点:
理解 MySQL InnoDB 的索引原理
掌握 MySQL 执行计划的方法
掌握导致索引失效的常见情况
掌握实际工作中常用的建立高效索引的技巧(如前缀索引、建立覆盖索引等)
在这之前我们需要先介绍一下索引相关的概念和知识。
相关概念
在实际应用中,InnoDB 是 MySQL 建表时默认的存储引擎,B+Tree 索引类型也是 MySQL 存储引擎采用最多的索引类型。
在创建表时,InnoDB 存储引擎默认使用表的主键作为主键索引,该主键索引就是聚簇索引(Clustered Index),如果表没有定义主键,InnoDB 就自己产生一个隐藏的 6 个字节的主键 ID 值作为主键索引,而创建的主键索引默认使用的是 B+Tree 索引。
索引分类:普通索引、唯一索引、全文索引、空间索引
- 在MySQL的官方文档中,create [option] index语法中,[option]就是用来修饰索引。
- 缺省代表普通索引
- unique代表唯一索引
- fulltext代表全文索引,全文索引目前通常采用ElasticSearch来实现,而不是在数据库内部来做
- spatial代表空间索引,而空间索引在一些老的MySQL版本中是不支持的,一般用于存储一些地址坐标数据
存储方式:B-Tree、Hash
- InnoDB支持B-Tree,不支持Hash
- InnoDB 选择 B+Tree 当默认的索引数据结构
- 数据存储有序(最左前缀与此息息相关)
- 每个叶子节点到根的距离相同
依赖列数:单列索引、组合索引
数据分布:聚簇索引、二级(辅助)索引
- 所谓聚簇索引就是指实际的数据行直接存到了叶子节点当中,而主键索引是聚簇索引的一个通常的形式。
- 通过主键查询数据,不需要回表,直接就可以得到数据行,效率较高。
- 非聚簇(主键)索引(辅助索引),叶子节点保存的不是最终的数据行,而只是一个主键值,需要通过主键值再去主键(聚簇)索引里查询最终叶子节点的数据行。因此需要走两次索引,是索引的索引,所以称为二级索引或辅助索引。这个过程叫回表。
回表情况:覆盖索引
当一个索引包含(覆盖)了需要查询的字段值时,称其为覆盖索引
只有select、where中出现的列被索引覆盖的情况才是覆盖索引
此时如果使用 explain 分析可以看到 Extra 的值为Using index
colums: a b c d e
index(a,b,c)
select a,b,c from T where a="" and b="";
最左前缀(Leftmost Prefixing)
table T,index(a,b,c) |
执行计划(explain)
了解完上面的概念之后,我们来介绍一下在实际工作中如何查看索引的执行计划。
我这里有一张存储用户信息的演示表 tab_user:
create table `tab_user` |
表中包含了主键索引、name 字段上的普通索引,以及 uid 和 name 两个字段的联合索引。现在我们来看一条简单查询语句的执行计划:
explain select uid,name from tab_user where uid='1'; |

对于执行计划,参数有 possible_keys 字段表示可能用到的索引,key 字段表示实际用的索引,key_len 表示索引的长度,rows 表示扫描的数据行数,filtered表示覆盖率%。Extra表示额外的信息说明。
这其中需要重点关注type字段,表示数据扫描类型,也就是描述了找到所需数据时使用的扫描方式是什么,常见扫描类型的执行效率从低到高的顺序为(考虑到查询效率问题,全表扫描和全索引扫描要尽量避免):
ALL(全表扫描);
index(全索引扫描);
range(索引范围扫描);
ref(非唯一索引扫描);
eq_ref(唯一索引扫描);
const(结果只有一条的主键或唯一索引扫描)。
总的来说,执行计划是研发工程师分析索引详情必会的技能(很多大厂公司招聘 JD 上写着“SQL 语句调优” ),所以你在面试时也要知道执行计划核心参数的含义,如 type。在回答时,也要以重点参数为切入点,再扩展到其他参数,然后再说自己是怎么做 SQL 优化工作的(讲个故事)。
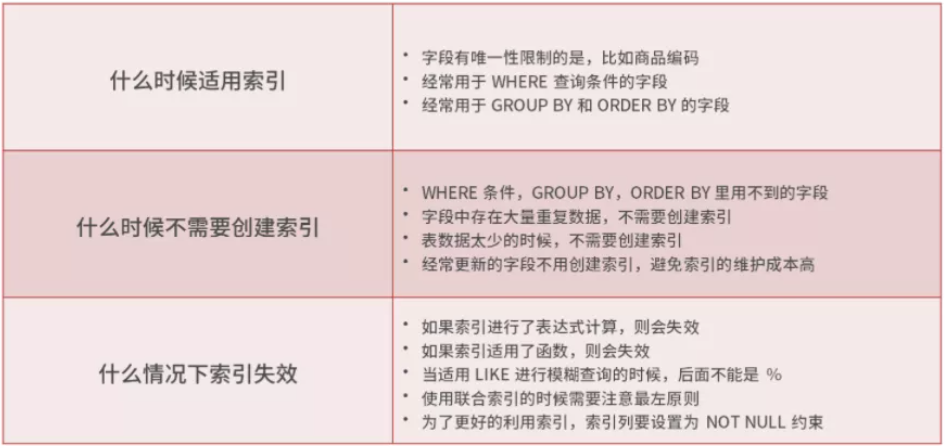
索引失效的常见情况
在工作中,我们经常会碰到 SQL 语句不适用已有索引的情况,来看一个索引失效的例子:
select * from tab_user where name like '%z' |
这条带有 like 查询的 SQL 语句,没有用到 tab_user 表中的 index_name 索引。

我们结合普通索引的B+Tree结构来分析一下索引失效的原因:当MySQL优化器根据name like ‘%z’这个条件,到索引index_name的B+Tree结构上去查询评估时,发现当前节点的左右子节点的值都有可能符合’%z’这个条件,于是优化器判定当前索引需要扫描整个索引,而且还要回表查询,不如直接全表扫描。
当然还有其他类似的索引失效的情况:
- 索引列上做了表达式计算、函数、隐式类型转换操作,这些情况下索引失效是因为查询过程需要扫描整个索引并回表,代价高于直接全表扫描;
- like匹配使用了左模糊查询(’%abc’)或左右模糊查询(’%abc%’);
- 字符串不加引号导致隐式类型转换;
- 被使用的索引字段不是联合索引的最左字段
总结:如果MySQL查询优化器预估走索引的代价比全表扫描的代价还要大,则不走对应的索引,直接扫描全表。如果走索引比全表扫描代价小,则使用索引。
常见优化索引的方法
前缀索引优化
前缀索引就是用某个字段中,字符串的前几个字符建立索引;使用前缀索引是为了减小索引字段大小,可以增加一个索引页中存储的索引值,有效提高索引的查询速度。在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
但是前缀索引有一定的局限性,例如 order by 就无法使用前缀索引,无法把前缀索引用作覆盖索引。
覆盖索引优化
覆盖索引是指 SQL 中 query 的所有字段,在索引 B+ Tree 的叶子节点上都能找得到的那些索引,从辅助索引中查询得到记录,而不需要通过聚簇索引查询获得。
假设我们只需要查询商品的名称、价格,有什么方式可以避免回表呢?
我们可以建立一个组合索引,即商品ID、名称、价格作为一个组合索引。如果索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表。所以,使用覆盖索引的好处很明显,即不需要查询出包含整行记录的所有信息,也就减少了大量的 I/O 操作。
联合索引
- 联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。
- 建立联合索引时的字段顺序,对索引效率也有很大影响。越靠前的字段被用于索引过滤的概率越高,实际开发工作中建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。

- 区分度就是某个字段 column 不同值的个数除以表的总行数,比如性别的区分度就很小,不适合建立索引或不适合排在联合索引列的靠前的位置,而 uuid 这类字段就比较适合做索引或排在联合索引列的靠前的位置。
小结